一文教你如何用代謝組學中層次聚類熱圖的R語言實現-pheatmap( )函數
在代謝組學的數據分析中,通常根據代謝物的含量進行層次聚類分析,以反映各個樣本之間代謝物含量的差異。
常用的數據分析工具中,R語言中的程序包可以靈活繪制出非常美觀的層次聚類熱圖形。本文將利用R語言中的pheatmap包對繪制層次聚類熱圖進行詳細的介紹(詳細參數見文末彩蛋!)
一、pheatmap( )函數常用參數簡介
pheatmap(mat, # 熱圖的輸入數據,數據類型為數值型data.frame或matrix
color = colorRampPalette(rev(brewer.pal(n = 7, name = "RdYlBu")))(100), # 熱圖顏色設置
cellwidth = NA, # 設置熱圖單元格的寬度
cellheight = NA, # 設置熱圖單元格的高度
treeheight_row = ifelse((class(cluster_rows) == "hclust") || cluster_rows, 50, 0), # 設置行聚類樹的高度
treeheight_col = ifelse((class(cluster_cols) == "hclust") || cluster_cols, 50, 0), # 設置列聚類樹的高度
cluster_rows = TRUE, # 是否對行進行聚類
cluster_cols = TRUE, # 是否對列進行聚類
cutree_rows = NA, # 設置將行聚類的結果分割成多少個集群,分割依據時基于層次聚類結果,如果未對行進行聚類,則該參數被直接忽略
cutree_cols = NA, # 設置將列聚類的結果分割成多少個集群,分割依據時基于層次聚類結果
annotation_row = NA, # 在熱圖左側添加注釋,可用于顯示代謝物的分類信息,數據為data.frame格式
annotation_col = NA, # 在熱圖頂部添加注釋,可用于顯示分組信息,數據為data.frame類型
border_color = "grey60", # 熱圖內部單元格的邊界顏色,可設置為NA無邊界
display_numbers = F, # 是否在熱圖單元格中顯示相應的數值
fontsize = 10, # 基礎字體大小設置
fontsize_row = fontsize, # 行名字體大小設置
fontsize_col = fontsize, # 列名字體大小設置
filename = NA, # 保存熱圖的全文件路徑,包含路徑和輸出的熱圖文件名(當設置了filename時,圖形顯示器將不再顯示熱圖
…)
二、pheatmap( )函數繪制熱圖實戰
第一步:安裝所需的R包及原始數據導入
install.packages("openxlsx") # 導入excel數據所需的R包
install.packages("pheatmap") # 繪制熱圖所需的R包
library(openxlsx)
library(pheatmap)
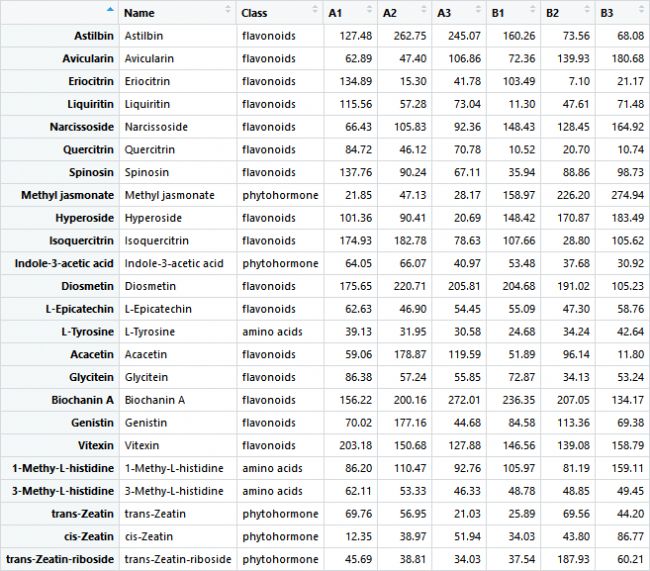
data <- read.xlsx(‘E: /R_TEST.xlsx’) # 導入數據(案例中的數據非真實數據)
rownames(data) <- data[, 1] # 設置行名
第二步:基礎熱圖-默認參數
pheatmap(data[, c(3:8)])
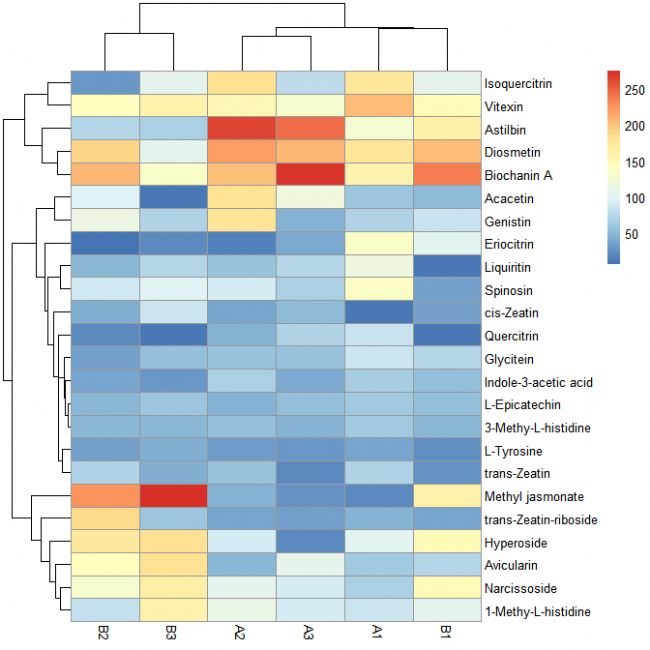
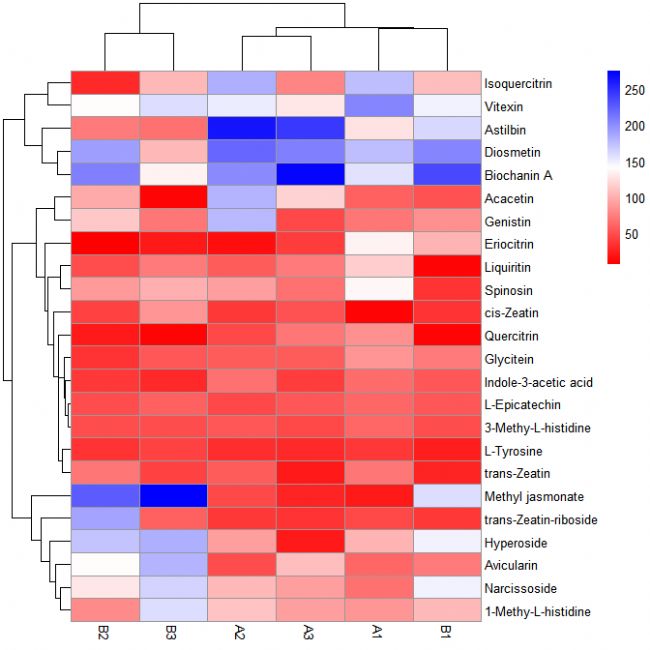
第三步:設置顏色
pheatmap(data[, c(3:8)], color = colorRampPalette(c('red', 'white', 'blue'))(100))
# 其中('red', 'white', 'blue')和(100)可根據需求自行修改
第四步:設置單元格大小
pheatmap(data[, c(3:8)], cellwidth = 18, cellheight = 18)
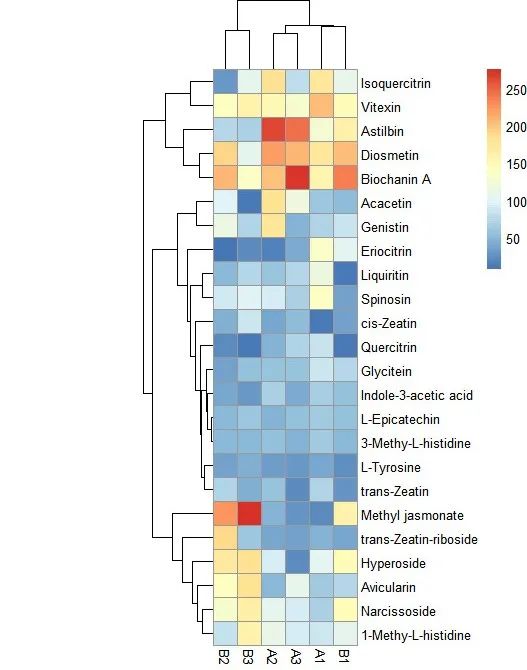
第五步:設置聚類樹的高度
pheatmap(data[, c(3:8)], treeheight_row = 100)
# 設置行(代謝物)聚類樹的高度
pheatmap(data[, c(3:8)], treeheight_col = 100)
# 設置列(樣本)聚類樹的高度
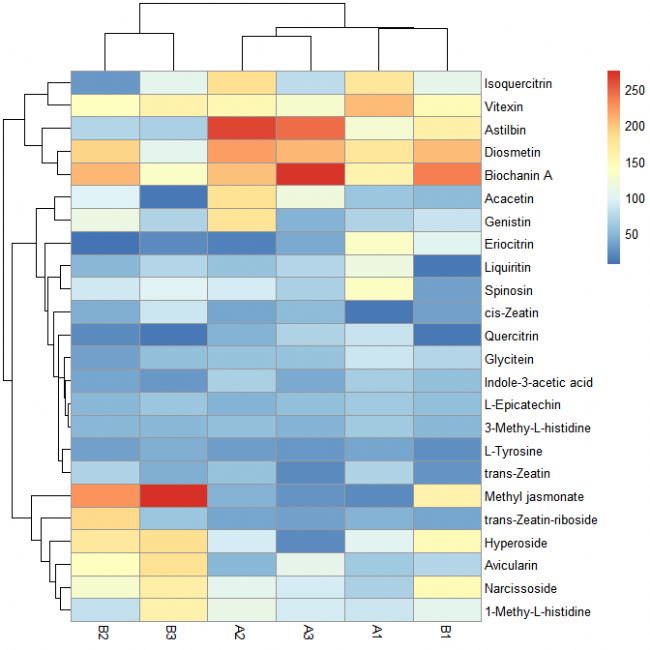
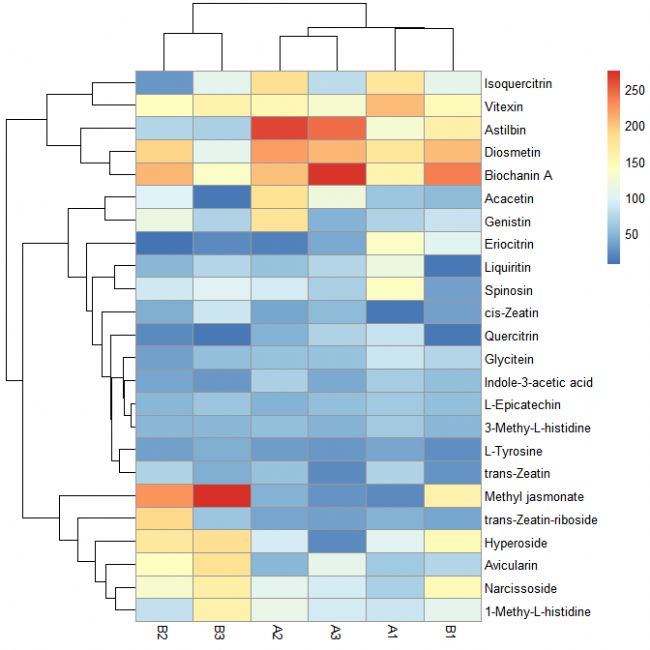
第六步:取消聚類
pheatmap(data[, c(3:8)], cluster_rows = FALSE)
# 取消行聚類
pheatmap(data[, c(3:8)], cluster_cols = FALSE)
# 取消列聚類
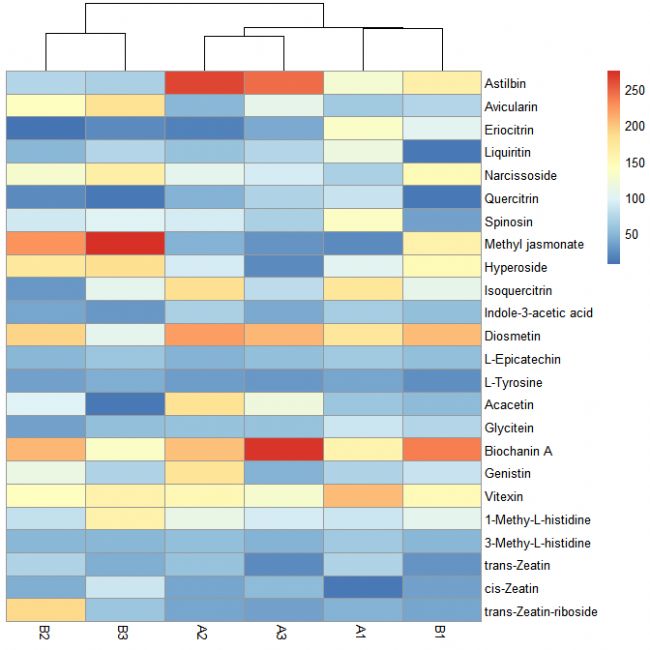
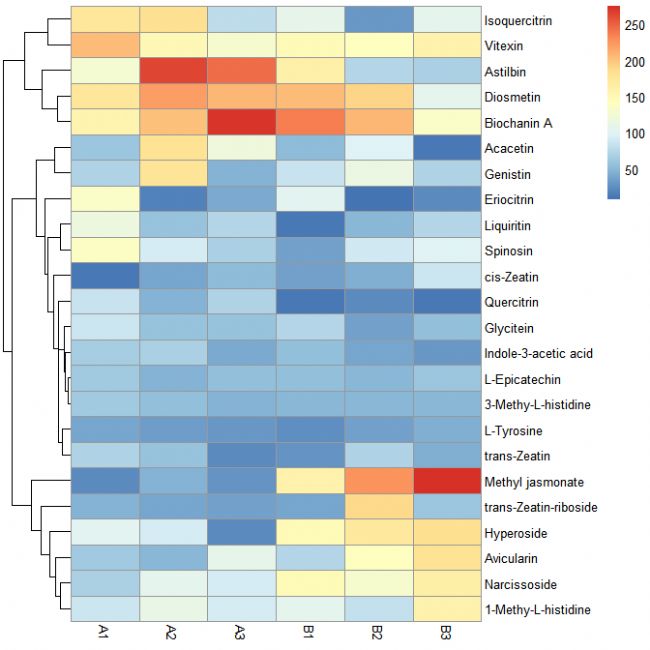
第七步:依據聚類結果對熱圖進行分割
pheatmap(data[, c(3:8)], cluster_rows = TRUE, cluster_cols = FALSE, cutree_rows = 3)
# cutree_rows = 3 是根據聚類結果進行的具體值設置
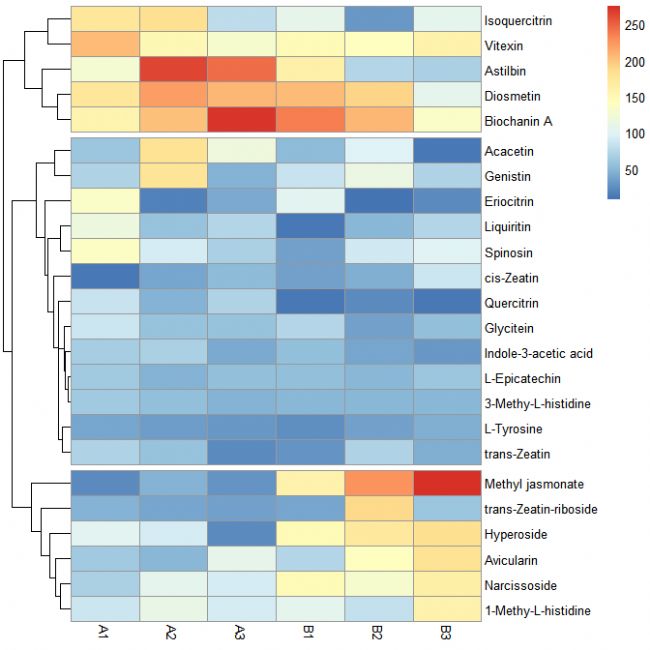
第八步:添加樣本分組信息
annotation_col = data.frame(Group = factor(rep(c('A','B'), c(3,3))), row.names = colnames(data[, c(3:8)]))
# 對每個樣本設置相對于的分組,(A、B為組名,3為每個組的樣本數)
注意:原始數據表中每個分組的樣本放在一起,否則factor( )需一一對應樣本名設置相對應的分組名。pheatmap(data[, c(3:8)], cluster_rows = TRUE, cluster_cols = FALSE, cutree_rows = 3, annotation_col = annotation_col)
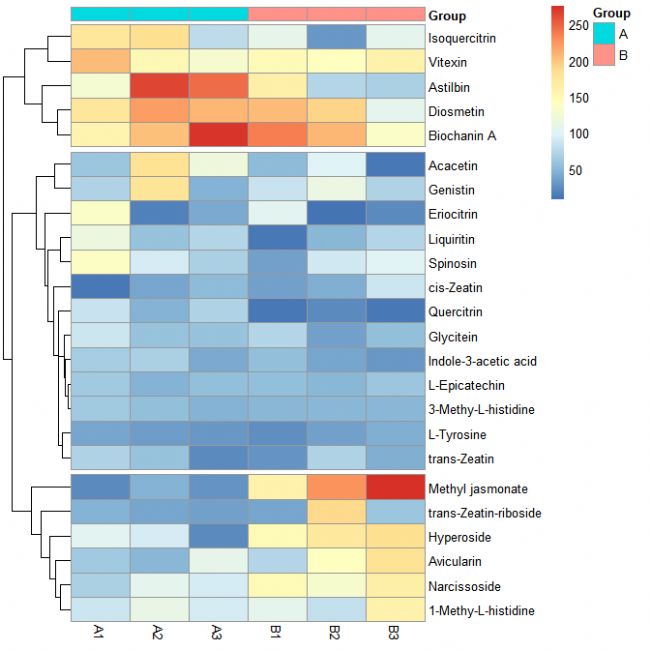
第九步:添加代謝物分類信息
annotation_row = data.frame(Class = data$Class, row.names = rownames(data))
pheatmap(data[, c(3:8)], cluster_rows = TRUE, cluster_cols = FALSE, cutree_rows = 3, annotation_col = annotation_col, annotation_row = annotation_row)
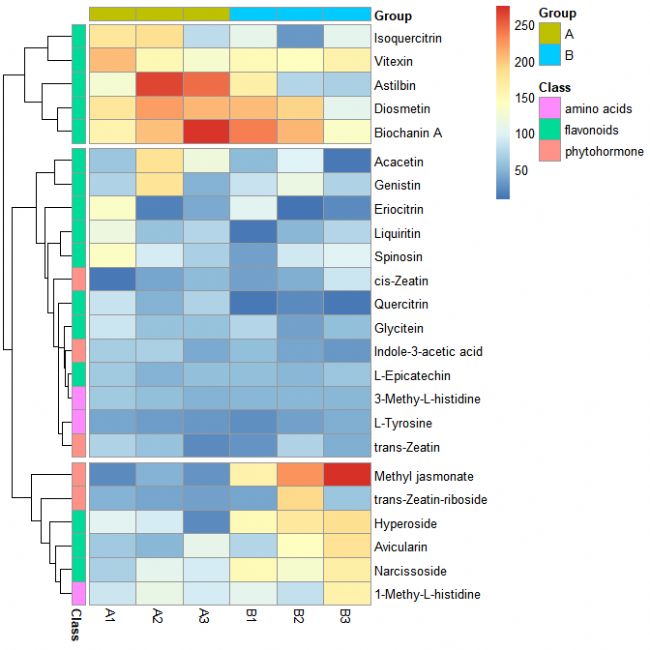
第十步:設置單元格邊框顏色,默認顏色為灰色(grey30)
pheatmap(data[, c(3:8)], cluster_rows = TRUE, cluster_cols = FALSE, cutree_rows = 3, annotation_col = annotation_col, annotation_row = annotation_row, border_color = NA)
# border_color = NA 表示不設置單元格邊框顏色
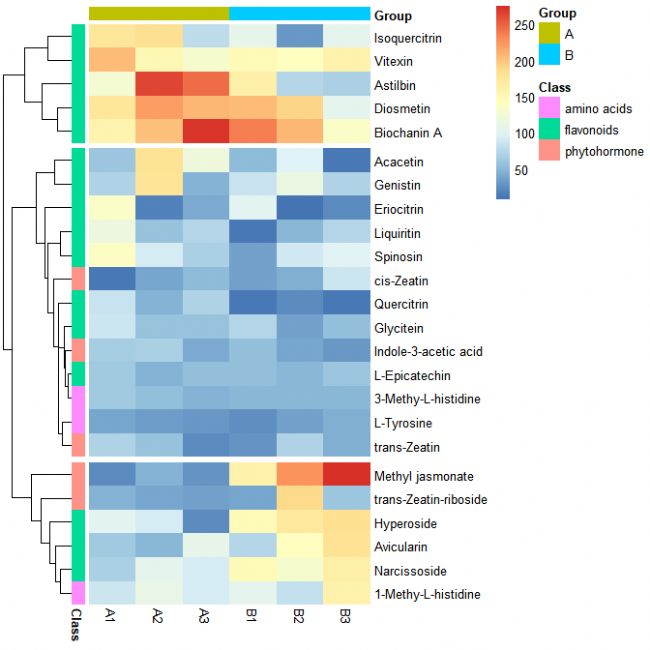
第十一步:單元格內顯示數值
pheatmap(data[, c(3:8)], cluster_rows = TRUE, cluster_cols = FALSE, cutree_rows = 3, annotation_col = annotation_col, annotation_row = annotation_row, border_color = NA, display_numbers = T)
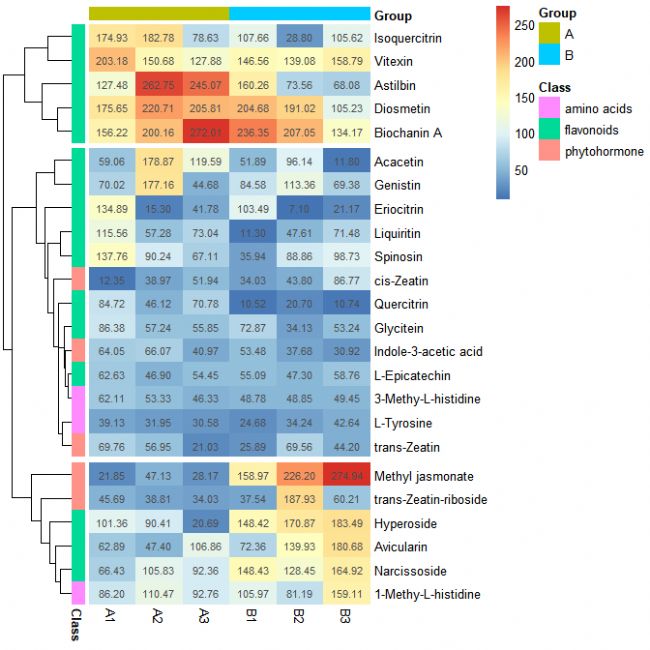
第十二步:設置字體大小
pheatmap(data[, c(3:8)], cluster_rows = TRUE, cluster_cols = FALSE, cutree_rows = 3, annotation_col = annotation_col, annotation_row = annotation_row, border_color = NA, display_numbers = T, fontsize = 11)
也可使用fontsize_row和fontsize_col分別對行標簽和列標簽進行字體大小設置。
pheatmap(data[, c(3:8)], cluster_rows = TRUE, cluster_cols = FALSE, cutree_rows = 3, annotation_col = annotation_col, annotation_row = annotation_row, border_color = NA, display_numbers = T, fontsize = 11, fontsize_row = 13, fontsize_col = 15)
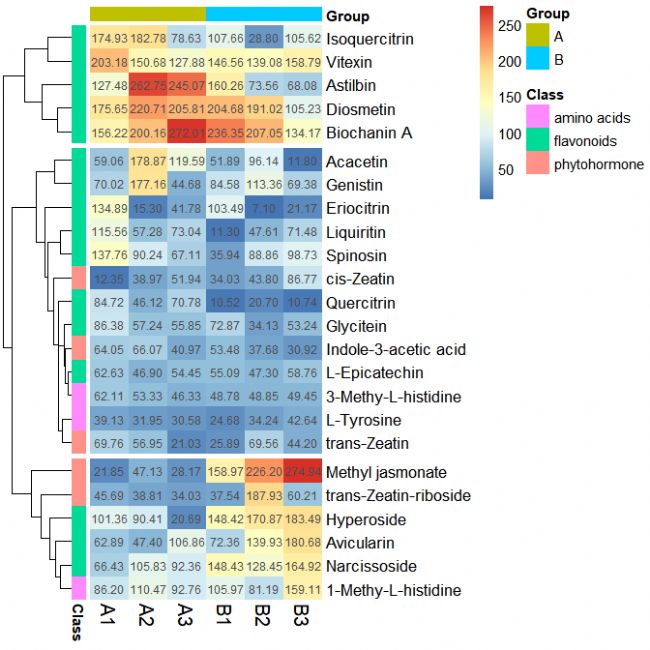
第十三步:保存熱圖
pheatmap(data[, c(3:8)], cluster_rows = TRUE, cluster_cols = FALSE, cutree_rows = 3, annotation_col = annotation_col, annotation_row = annotation_row, border_color = NA, display_numbers = T, filename = 'E:/R_TEST.png')
# filename為保存路徑和文件名
注意:設置filename后,RStudio圖形界面將不再顯示出熱圖。
彩蛋:pheatmap( )函數的參數詳解
網盤下載鏈接:
https://pan.baidu.com/s/1ao690Lpk2upH57_pu5AElw
提取碼:98e4